- What Is an AI Native Software Stack?
- The Old Stack vs the AI Native Software Stack
- The Orchestration Layer: The New Center of the Stack
- Where AI Agents Fit in the Architecture
- The Knowledge Layer: Why Your Data Architecture Changes
- Why Architecture Matters More With AI, Not Less
- How to Build an AI-Native Application
- Anti-Patterns in AI-Native System Design
- Key Takeaways
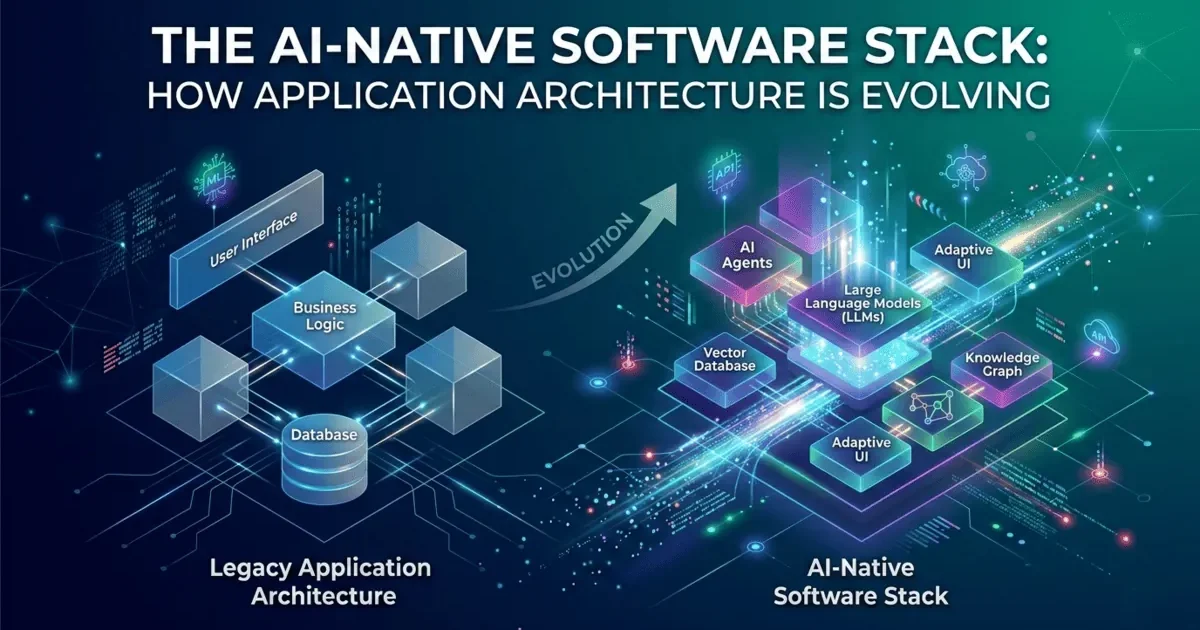
An AI native software stack is an application architecture designed from the ground up to incorporate AI components as first-class citizens, not bolted-on features. The traditional software stack — frontend, backend, database — was designed for a world where all logic was written by humans and all data flowed through predetermined paths. The AI native software stack adds new layers: an orchestration layer that coordinates AI agents, a knowledge layer that provides context through embeddings and retrieval, and integration patterns that handle the inherent unpredictability of AI outputs.
I have been building AI-powered tools and workflows for over three years now, and the biggest lesson is this: you cannot just add AI to a traditional architecture and expect it to work well. AI components behave differently from traditional software. They are probabilistic, not deterministic. Their outputs vary. They have latency characteristics that differ from database queries. They cost money per call. Treating AI as just another API call leads to architectures that are fragile, expensive, and unreliable. The AI native software stack addresses these realities from the start.
What Is an AI Native Software Stack?
A traditional software stack is a collection of technologies layered together to build an application. The classic web stack — frontend framework, backend API, and relational database — has been the standard for two decades. It is well-understood, well-documented, and well-tooled.
An AI native software stack extends this foundation with layers specifically designed for AI workloads. It is not a replacement for the traditional stack — it is an evolution that adds capabilities the traditional stack was never designed to handle.
The AI native software stack has three additional layers that the traditional stack lacks: the orchestration layer, the AI services layer, and the knowledge layer. Each addresses a specific challenge that AI components introduce.
The Old Stack vs the AI Native Software Stack: A Detailed Comparison
| Concern | Traditional Stack | AI Native Software Stack |
|---|---|---|
| Request handling | Deterministic — same input, same output | Probabilistic — same input, varying output |
| Latency | Milliseconds (database queries) | Seconds (LLM API calls) + milliseconds |
| Cost per request | Compute + bandwidth (fractions of a cent) | Compute + bandwidth + token costs ($0.01-$0.10 per call) |
| Error handling | Deterministic errors with clear causes | Probabilistic failures — hallucinations, quality degradation |
| Data flow | Request → Process → Store → Respond | Request → Retrieve Context → AI Process → Validate → Store → Respond |
| Caching strategy | Cache responses by input | Cache embeddings, cache similar-enough queries, invalidate on context change |
| Scaling concern | Requests per second, database connections | Token throughput, API rate limits, embedding compute, vector DB capacity |
| Testing | Assert exact outputs | Assert output quality ranges, validate structure, check safety |
Every row in this table represents a design decision that changes when you build an AI native software stack. The shift from deterministic to probabilistic behavior alone requires fundamental rethinking of how you handle errors, test code, and set user expectations. You cannot test an AI native system the same way you test a traditional application because the outputs are not identical on every run.
The Orchestration Layer: The New Center of the AI Native Software Stack
The orchestration layer is the most important addition in the AI native software stack. It sits between your backend API and the AI services, managing the complexity of coordinating multiple AI components.
Think of it this way: in a traditional stack, your backend API calls the database, gets data, processes it, and returns a response. The logic is straightforward and synchronous. In an AI native software stack, a single user request might require:
- Retrieving relevant context from a vector database
- Calling an LLM with the context and user query
- Validating the LLM response for safety and accuracy
- Possibly calling a second LLM to refine the response
- Storing the interaction for future context
- Handling failures at any step gracefully
The orchestration layer manages this entire flow. It handles retry logic when AI calls fail. It routes requests to different models based on complexity or cost. It implements circuit breakers when an AI service is overloaded. It manages the conversation context that makes AI responses coherent across interactions.
Without an orchestration layer, all of this logic gets scattered across your backend API handlers. You end up with AI calls mixed into business logic, retry logic duplicated across endpoints, and inconsistent error handling. The orchestration layer centralizes AI-specific concerns the same way a database layer centralizes data access concerns.
Where AI Agents Fit in the AI Native Software Stack
An AI agent is an AI system that can take autonomous actions — reading data, calling APIs, modifying files, making decisions. Agents are a step beyond simple LLM calls. Instead of “generate text given this prompt,” an agent can “research this topic, draft a report, verify the facts, and publish it.”
In the AI native software stack, agents live within the orchestration layer but have their own execution patterns:
| Component | Simple LLM Call | AI Agent |
|---|---|---|
| Input | Single prompt with context | Goal or task description |
| Execution | One request, one response | Multiple steps with tool usage |
| Decision making | None — generates text only | Decides which tools to use, when to stop |
| Duration | Seconds | Minutes to hours |
| Resource usage | Predictable (one API call) | Variable (many API calls, tool invocations) |
| Error handling | Retry the one call | Agent may need to backtrack and try different approach |
| Architecture needs | Simple request-response | Task queue, state management, execution monitoring |
When your AI native software stack includes agents, the orchestration layer needs additional capabilities: task queuing (agents take minutes, not seconds), state management (agents need to remember what they have done), execution monitoring (you need to know what agents are doing), and kill switches (you need to stop agents that go off track). These are not trivial additions — they represent a significant architectural investment.
The Knowledge Layer: Why Your Data Architecture Changes
The knowledge layer is what makes AI native applications intelligent rather than just AI-powered. It provides the context that transforms generic AI responses into specific, accurate, and useful outputs.
In a traditional stack, your database stores structured data — rows and columns with defined schemas. In an AI native software stack, you also need:
Vector databases for semantic search. Traditional databases find exact matches. Vector databases find semantic matches — content that is similar in meaning, not just identical in text. When a user asks “how do I handle authentication,” the vector database retrieves documents about auth patterns, security, JWT tokens, and session management — even if those documents never use the exact word “authentication.”
Embedding pipelines for knowledge ingestion. Before your knowledge base can be searched semantically, documents must be converted into vector embeddings. This is a data pipeline in itself — chunking documents, generating embeddings, storing them with metadata, and keeping them updated as source material changes. As we covered in Building AI-Ready ETL Pipelines, this pipeline needs the same engineering rigor as any ETL system.
Context management for conversations. AI conversations need memory. The knowledge layer stores conversation history, user preferences, and session state so that AI responses build on previous interactions rather than starting from zero every time. This is the context engineering challenge applied at the infrastructure level.
| Knowledge Layer Component | Purpose | Technology Examples |
|---|---|---|
| Vector Database | Semantic search over documents and context | Pinecone, Weaviate, pgvector, Qdrant |
| Embedding Pipeline | Convert documents to searchable vectors | OpenAI embeddings, Cohere, local models |
| Context Store | Conversation history, user preferences | Redis, PostgreSQL, dedicated context DB |
| Document Store | Source documents for RAG retrieval | S3, MinIO, document DB |
| Cache Layer | Frequently accessed embeddings and responses | Redis, Memcached |
Why Architecture Matters More With AI, Not Less
There is a common misconception that AI makes architecture less important. The thinking goes: if AI can generate code for any pattern, why worry about architectural choices? The reality is exactly the opposite. Architecture matters more in an AI native software stack because:
AI amplifies architectural decisions. A good architecture with AI tools produces high-quality systems fast. A poor architecture with AI tools produces high-volume garbage fast. AI does not fix bad architecture — it scales it. If your orchestration layer has no retry logic, every AI failure crashes your user experience. If your knowledge layer has stale embeddings, every AI response uses outdated information. Architecture determines whether AI makes your system better or worse.
AI components are more unpredictable than traditional components. A database query either succeeds or fails with a clear error. An AI call can succeed but return a subtly wrong answer. It can succeed but take 30 seconds instead of 3. It can succeed but cost 10 times more than expected because the input was longer than usual. Your architecture must handle this unpredictability with circuit breakers, fallbacks, cost limits, and quality validation — none of which the traditional stack needed.
The cost of rearchitecting AI systems is higher. Traditional systems can often be refactored incrementally. AI native systems have deeply interconnected layers — your orchestration layer depends on your knowledge layer, which depends on your embedding pipeline, which depends on your document store. Changing one layer often requires changes across the entire AI native software stack. Getting the architecture right early saves enormous cost later.
How to Build an AI Native Application: A Practical Approach
If you are building an AI native application, here is the approach I recommend based on what has actually worked:
Start with the traditional stack. Get your backend API, database, and frontend working first. Do not start with AI. Start with a system that works without AI. This gives you a solid foundation and clear boundaries for where AI will be added.
Add the knowledge layer second. Set up your vector database, build your embedding pipeline, and get semantic search working. This is the foundation that makes AI responses intelligent rather than generic. Without it, your AI components are just expensive text generators.
Build the orchestration layer third. Create a clean abstraction between your backend and AI services. Include routing, retry logic, fallbacks, cost tracking, and response validation from the start. Do not scatter AI calls throughout your backend — centralize them.
Add AI agents last. Agents are the most complex component. They require task queuing, state management, monitoring, and safety controls. Only add agents after the simpler components are stable and well-understood.
Anti-Patterns in AI Native System Design
| Anti-Pattern | What It Looks Like | Why It Fails | What to Do Instead |
|---|---|---|---|
| AI Everywhere | Every feature uses AI even when simple logic works | Increases latency, cost, and unpredictability unnecessarily | Use AI only where it adds value over deterministic logic |
| No Orchestration Layer | AI calls scattered across backend handlers | Inconsistent error handling, duplicated retry logic, impossible to monitor | Centralize all AI interactions through orchestration layer |
| Trusting AI Output | Passing AI responses directly to users without validation | Hallucinations, unsafe content, and format errors reach users | Always validate AI output before presenting to users |
| No Cost Controls | Unlimited AI API calls per request | A single runaway request or loop can cost hundreds of dollars | Set per-request and daily token limits, implement circuit breakers |
| Stale Knowledge | Embedding pipeline runs once, never updated | AI responses based on outdated information erode user trust | Build incremental update pipeline, track document freshness |
| Agent Without Guardrails | AI agents with unrestricted tool access | Agents can take destructive actions, access sensitive data, or loop indefinitely | Sandbox agent tools, set execution limits, require human approval for sensitive actions |
Key Takeaways
- The AI native software stack adds three layers to the traditional stack: An orchestration layer for managing AI interactions, a knowledge layer for context and semantic search, and an AI services layer for model access. These are not optional — they address real architectural challenges.
- AI components are probabilistic, not deterministic: This fundamental difference affects every design decision — error handling, testing, caching, cost management, and user experience. Your architecture must account for variability.
- The orchestration layer is the most critical addition: It centralizes retry logic, model routing, cost controls, and response validation. Without it, AI concerns leak into every part of your backend.
- The knowledge layer makes AI responses intelligent: Vector databases, embedding pipelines, and context management transform generic AI into context-aware AI. Without the knowledge layer, AI is just an expensive text generator.
- Architecture matters more with AI, not less: AI amplifies your architectural choices. Good architecture with AI produces great systems fast. Bad architecture with AI produces expensive garbage fast.
- Build in order: foundation, knowledge, orchestration, then agents: Start with a working system without AI. Add AI components layer by layer, ensuring each layer is stable before adding the next.
- Always validate AI output before it reaches users: Hallucinations, format errors, and unsafe content are not edge cases — they are expected behavior that your architecture must handle.


