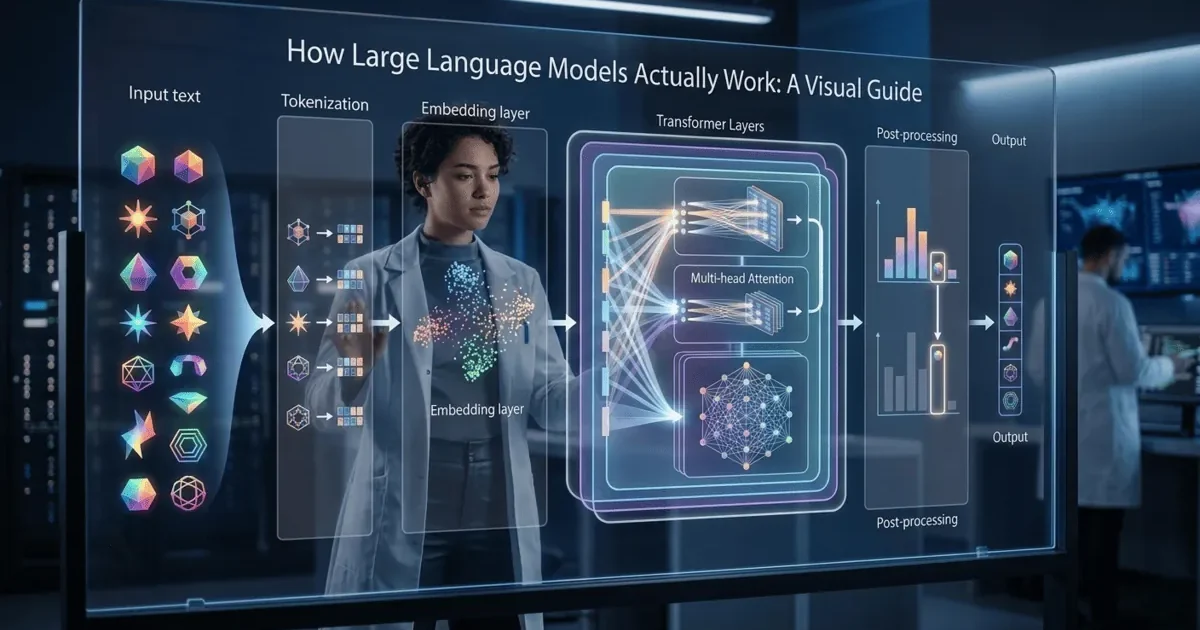
- What Is a Large Language Model?
- How Do LLMs Learn? The Training Loop Explained
- What Are Tokens and Why Do They Matter?
- What Are Weights and Parameters?
- How Does the Attention Mechanism Work?
- How Does Text Generation Actually Happen?
- How Do Current LLMs Compare?
- Common Misconceptions About LLMs
- Try It Yourself: Interactive Visual Guide
- Key Takeaways
You have used ChatGPT, Claude, or Gemini. You have asked questions, generated text, maybe even used them to help write code. But do you actually understand how LLMs work under the hood? Most people do not. They use the term “AI” like it is magic. But there is no magic here. Just mathematics, executed at extraordinary scale. And understanding that mathematics, even at a high level, will fundamentally change how you use these tools.
This guide will show you how LLMs work at every level. Not through equations you will forget by tomorrow. Through clear explanations of what happens under the hood, step by step, with real values you can follow. I have also built an interactive visual guide where you can explore these concepts hands-on.
What Is a Large Language Model?
Large Language Model — This sounds intimidating, but it is really just this: a program that predicts the next word in a sequence, trained on enormous amounts of text. That is the entire core idea. Everything else is about making that prediction better.
When you type “The capital of France is” into ChatGPT, the model does not “know” geography. It has learned, from billions of text examples, that the word “Paris” almost always follows that sequence. It is pattern matching at a scale that produces behavior which looks like understanding.
| Term | What It Actually Means | Analogy |
|---|---|---|
| Model | A mathematical function with billions of adjustable numbers | A recipe with billions of ingredient amounts to tune |
| Large | Billions of parameters (adjustable numbers) | GPT-4 has ~1.8 trillion parameters across multiple experts |
| Language | Trained on and generates human language text | It learned by reading most of the internet |
| Training | The process of adjusting parameters to minimize prediction errors | Studying for an exam by checking answers and correcting mistakes |
The key insight that changed my understanding of how LLMs work: they do not store facts like a database. They store patterns — statistical relationships between words and concepts. When those patterns are strong (trained on thousands of similar examples), the model appears knowledgeable. When patterns are weak or conflicting, the model hallucinates confidently.
How Do LLMs Learn? The Training Loop Explained
To understand how LLMs work, you need to understand one fundamental loop that every AI system uses, from the simplest classifier to the most sophisticated language model:
Predict → Measure Error → Adjust → Repeat
That is it. That is the entire field of machine learning in four words. Let me walk through exactly what happens during training.
Training text: "The cat sat on the mat"
Step 1: Model sees "The"
→ Predicts next word: "dog" (random early guess)
→ Actual next word: "cat"
→ Error: HIGH (wrong word)
→ Adjusts internal weights slightly toward "cat"
Step 2: Model sees "The cat"
→ Predicts next word: "ran" (slightly better guess)
→ Actual next word: "sat"
→ Error: MEDIUM
→ Adjusts weights again
Step 3: After seeing millions of similar sentences...
→ Model sees "The cat sat on the"
→ Predicts: "mat" (0.35), "floor" (0.28), "bed" (0.15), ...
→ Actual: "mat"
→ Error: LOW (correct prediction, high confidence)
This process repeats billions of times across trillions of words.The mechanism that controls the adjustment is called gradient descent. Think of it like this: imagine you are blindfolded on a hilly landscape, trying to find the lowest valley. You cannot see, but you can feel the slope under your feet. You take a small step downhill. Then another. Then another. Gradient descent does exactly this, but in a space with billions of dimensions instead of three.
The “gradient” is the slope. The “descent” is walking downhill. The “valley” is where prediction errors are minimized. Training is just walking downhill for a very long time.
What Are Tokens and Why Do They Matter?
Token — This word appears everywhere in AI discussions, but it is really just this: a chunk of text that the model treats as a single unit. Not quite a word, not quite a character. Something in between.
LLMs do not read text the way humans do. They break text into tokens first, then convert those tokens into numbers. The model only works with numbers internally.
"Hello world" → ["Hello", " world"] → 2 tokens
"ChatGPT is great" → ["Chat", "G", "PT", " is", " great"] → 5 tokens
"I don't know" → ["I", " don", "'t", " know"] → 4 tokens
"Tokenization" → ["Token", "ization"] → 2 tokens
"supercalifragilistic" → ["super", "cal", "if", "rag", "il", "istic"] → 6 tokens
Rule of thumb: 1 token ≈ 0.75 words (or about 4 characters in English)
1,000 tokens ≈ 750 wordsWhy does tokenization matter for understanding how LLMs work? Because everything in an LLM is measured in tokens. The context window (how much text the model can see at once) is measured in tokens. The cost of API calls is measured in tokens. The speed of generation is measured in tokens per second. Understanding tokenization helps you understand the economics and constraints of every AI interaction.
What Are Weights and Parameters?
Parameters — Another term that sounds complex but is really just this: numbers that the model adjusts during training. Billions of them. Each one slightly influences how the model makes predictions.
Here is an analogy that mirrors what actually happens. Imagine you are trying to predict house prices based on two factors: square footage and number of bedrooms.
Price = (square_feet × weight_1) + (bedrooms × weight_2) + bias
Start with random weights:
weight_1 = 0.5, weight_2 = 100, bias = 10000
Training example: 1500 sq ft, 3 bedrooms, actual price = $300,000
Prediction: (1500 × 0.5) + (3 × 100) + 10000 = $11,050
Error: $300,000 - $11,050 = $288,950 (way off!)
Adjust weights (gradient descent):
weight_1 = 150, weight_2 = 10000, bias = 50000
New prediction: (1500 × 150) + (3 × 10000) + 50000 = $305,000
Error: $300,000 - $305,000 = -$5,000 (much closer!)
After thousands of examples, weights settle to values that minimize error.Understanding how LLMs work at the parameter level: an LLM operates exactly the same way, except instead of 2 weights for house prices, it has billions of weights for language patterns. GPT-4 has an estimated 1.8 trillion parameters. Claude 3.5 Sonnet is estimated at around 70 billion. Each parameter is a single number, typically stored as a 16-bit floating point value. That means GPT-4’s “knowledge” is stored in roughly 3.6 terabytes of numbers.
How Does the Attention Mechanism Work?
Attention — This is the breakthrough that made modern LLMs possible. It is really just this: a way for the model to decide which words in the input are most relevant to predicting the next word.
To truly understand how LLMs work, you need to understand attention. Before attention, models processed text sequentially, one word at a time, like reading a book from left to right. The problem was that by the time the model reached word 100, it had largely forgotten word 5. Attention solved this by letting the model look at all words simultaneously and assign importance scores to each one.
Input: "The bank by the river was flooded"
When predicting what "bank" means, the model assigns attention scores:
"The" → 0.02 (low relevance)
"bank" → 0.15 (the word itself)
"by" → 0.05 (low relevance)
"the" → 0.03 (low relevance)
"river" → 0.45 (HIGH - tells us this is a river bank, not a financial bank)
"was" → 0.10 (moderate)
"flooded" → 0.20 (confirms the river bank interpretation)
The word "river" gets the highest attention score because it is
most relevant for understanding what "bank" means in this context.
This happens for EVERY word, simultaneously, across multiple
"attention heads" that each look for different patterns.The 2017 paper “Attention Is All You Need” introduced the Transformer architecture, which uses attention as its core mechanism. Every modern LLM, including GPT-4, Claude, Gemini, and Llama, is built on this architecture. The name “Transformer” comes from how it transforms input sequences into output sequences using attention.
How Does Text Generation Actually Happen?
When you send a message to an LLM, here is what happens under the hood. Understanding how LLMs work at the generation level reveals the process that produces every AI response you have ever seen.
Your prompt: "Explain why the sky is"
Step 1: Model processes all tokens in your prompt
→ Runs through ~96 transformer layers (for GPT-4 scale)
→ Produces probability distribution for next token
→ Output: "blue" (0.72), "dark" (0.08), "red" (0.05), ...
→ Selects: "blue"
Step 2: Append "blue" to context → "Explain why the sky is blue"
→ Process entire sequence again
→ Predict next token
→ Output: "." (0.31), ":" (0.15), "\n" (0.12), ...
→ Selects: "."
Step 3: Append "." → "Explain why the sky is blue."
→ Process entire sequence again
→ Predict next token
→ Output: "The" (0.28), "When" (0.15), "\n" (0.22), ...
→ Selects: "\n\n" then "The"
This continues token by token until the model generates a stop token
or reaches the maximum length. A 500-word response requires ~670
individual prediction steps.This is called autoregressive generation. “Auto” because it feeds its own output back as input. “Regressive” because each step depends on all previous steps. The model literally writes one token at a time, each time reconsidering everything it has written so far.
This is why LLMs sometimes start a sentence well but end it poorly. By the time they reach the end, the beginning has less influence on each new prediction. It is also why longer responses cost more: each token requires processing the entire sequence up to that point.
How Do Current LLMs Compare?
| Model | Parameters (Est.) | Context Window | Strengths |
|---|---|---|---|
| GPT-4o | ~1.8T (MoE) | 128K tokens | Broad knowledge, multimodal, strong reasoning |
| Claude Opus 4 | Not disclosed | 200K tokens | Long-form analysis, instruction following, coding |
| Gemini 1.5 Pro | Not disclosed | 1M+ tokens | Massive context, multimodal, Google integration |
| Llama 3.1 405B | 405B | 128K tokens | Open source, self-hostable, strong performance |
| Mistral Large | ~123B | 128K tokens | Efficient, multilingual, good value |
When comparing how LLMs work across providers, note that most companies do not disclose exact parameter counts, and “bigger” does not always mean “better.” GPT-4 uses a Mixture of Experts (MoE) architecture, meaning only a fraction of its 1.8 trillion parameters activate for any given query. A well-trained 70B parameter model can outperform a poorly trained 200B model on specific tasks. Architecture and training data quality matter as much as raw size.
What Do Most People Get Wrong About LLMs?
| What People Think | What Actually Happens |
|---|---|
| “AI understands what I am saying” | LLMs process statistical patterns in token sequences. They do not understand meaning the way humans do. |
| “AI knows facts” | LLMs store patterns, not facts. They can generate text that sounds factual but is statistically plausible fiction. |
| “Bigger models are always better” | Architecture, training data quality, and fine-tuning matter as much or more than parameter count. |
| “AI thinks before responding” | LLMs generate text one token at a time. There is no “thinking” step. Each token is a prediction based on everything before it. |
| “AI remembers our conversation” | LLMs are stateless. They re-read the entire conversation from scratch with every message. Memory is simulated by including history in the context. |
| “AI is creative” | LLMs recombine patterns from training data. Novel-seeming outputs are novel combinations of existing patterns, not genuine creativity. |
Understanding how LLMs work at this level does not make them less useful. It makes you more effective at using them. Once you know how LLMs work internally, you structure your prompts to activate the right patterns. When you know it is stateless, you provide the context it needs. When you know it can hallucinate, you verify critical outputs.
Try It Yourself: Interactive Visual Guide
Reading about how LLMs work is useful. But seeing it happen is better. I have built an interactive visual guide that lets you explore each concept hands-on:
- Adjust weights in real-time and see how predictions change
- Watch the learning loop as gradient descent finds better values
- Type your own text and see how tokenization breaks it apart
- Trace data flow through a neural network layer by layer
- See text generation happen one token at a time
Understanding how LLMs work builds from interaction. The visualizations are designed to give you intuition that no amount of reading can provide.
Key Takeaways
- LLMs are next-token predictors: At their core, they predict the most likely next word given all previous words. Understanding how LLMs work starts with this basic idea.
- The training loop is simple — Predict, Error, Adjust, Repeat: This loop, executed billions of times across trillions of words, is what produces language models that appear intelligent.
- Tokens are the fundamental unit: Everything, including context windows, costs, and speed, is measured in tokens. One token is roughly 0.75 words.
- Attention is the key breakthrough: It lets the model decide which parts of the input matter most for each prediction, enabling it to handle context and ambiguity.
- Text generation is one token at a time: There is no batch output. Each token depends on everything generated before it, which is why responses can degrade over length.
- LLMs do not understand, they pattern-match: This is not a limitation to work around. It is the fundamental architecture to work with. Knowing how LLMs work makes you a better user.
- Understanding the mechanics changes how you use the tools: Better prompts, better context management, and realistic expectations all come from understanding what happens under the hood.

